Recently, my colleague and fellow blogger Alyssa Frazee accepted a job at Stripe. All of us at JHU Biostat are happy for her, yet sad to see her go.
While perusing Stripe’s website, I found the About page, where each employee has a photo of themselves. I’ve been playing around with some PCA and decompositions, so I figured I’d play around with these photos and make some principal components/eigenfaces. (I think it’s funny when people use the SVD/Eigenvalue decomposition in a new field and name the new thing the eigen-whatever.)
Extracting the HTML
In order to get the images, I had to scrape the about page for links.
Let’s note that stripe uses https and not http for their website (not surprisingly as they do secure payment systems).
library(RCurl)
library('httr')
library('XML')
url.stub = 'https://stripe.com/'
As they use https, you cannot simply read the data into R using readLines or other functions. For this, I used curl in the RCurl package. I defined my certification, got the page, extracted the content as a character vector (imaginatively named x), then parsed the HTML using the XML pagckage.
cafile <- system.file('CurlSSL', 'cacert.pem', package = 'RCurl')
# Read page
page <- GET(
url.stub,
path='about',
config(cainfo = cafile)
)
x <- content(page, as='text')
#########################
# Parse HTML
#########################
doc <- htmlTreeParse(x, asText=TRUE, useInternal=TRUE)
Extracting Image Links
Now that I have parsed the HTML document, I can use XPath. If you look at the source of the HTML, there is a div with the id of about, which contains all the links. The xpathSApply function takes the document, the XPath query, which says I want to go to that div, grab all img tags and then get the src.
#########################
# Get face URLs
#########################
stub = "//div[@id = 'about']"
urls = xpathSApply(doc,
path=paste0(stub, '//img'),
xmlGetAttr, 'src')
I then created an output directory imgdir where I’ll store the images (stored as pngs). Below is just some checking to see if I have already downloaded (in case I had to re-run the code) and only downloads images I don’t already have.
img.urls = paste0(url.stub, urls)
out.imgs = file.path(imgdir, basename(img.urls))
stopifnot(!any(duplicated(img.urls)))
have = file.exists(out.imgs)
img.urls = img.urls[!have]
out.imgs = out.imgs[!have]
###########
# Download images
##########
for (iimg in seq_along(img.urls)){
download.file(url=img.urls[iimg], destfile = out.imgs[iimg],
method='curl')
}
Again, since Stripe uses https, we cannot just use download.file with the default method. I again used curl to get the images. I (manually) downloaded and cropped the image from Alyssa’s biostat page to add her to the Stripe set.
Analyze the Images
I now take all the images, read them in using readPNG. readPNG returns an array, and the first 3 dimensions are the RGB if the image is color; they are not 3D arrays if the images are grayscale, but none in this set are. The 4th dimension is the alpha level if there is opacity, but this information is discarded in the readPNG(img.f)[, , 1:3] statement.
library(png)
library(pixmap)
library(matrixStats)
imgs = list.files(imgdir, pattern='.png$', full.names = TRUE)
n_imgs = length(imgs)
img.list = vector(mode= 'list', length = n_imgs)
iimg = 2
for ( iimg in seq(n_imgs)){
img.f = imgs[iimg]
img.list[[iimg]] = readPNG(img.f)[, , 1:3]
}
Same Image Size
To make things easier, I only kept images that were 200 pixels by 200 pixels, so each image was the same size. If you had images of different sizes, you may want to do interpolation to get the same size and resolution.
dims = lapply(img.list, dim) ################################ # Don't feel like interpolating - only keeping 200x200x3 ################################ dimg = c(200, 200, 3) keep = sapply(dims, function(x) all(x == dimg)) img.list = img.list[keep] imgs = imgs[keep] dims = dims[keep]
We then make a matrix of 12000 by N (N = 167), where the rows are the concatenated values from the red, green, and blue values.
################################ # Making Matrix: P x N ################################ mat = t(sapply(img.list, c)) cmeans = colMeans(mat) sds = colSds(mat)
Mean Image
A small function makeimg takes in a vector/matrix, creates an array of 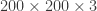
pixmapRGB from the pixmap package. Here we plot the “Average Striper”.
makeimg = function(x, trunc = FALSE, ...){
x = array(x, dim = dimg)
if (trunc){
x[x < 0] = 0
x[x > 1] = 1
}
plot(pixmapRGB(x), ...)
}
makeimg(cmeans, main = 'Average Striper')

PCA
Although this is what’s in common for Stripe pictures, let’s do a quick PCA (or equivalently SVD) to get the principal components after centering and scaling our data to see what’s different:
# ############# # # Centering and scaling matrix # ############# X = t(t(mat) - cmeans) X = t(t(X) / sds) pca = prcomp(X, center=FALSE)
We can get the percent variance explained from standardized eigenvalues (proportional to the squared deviances), or just use screeplot:
devs = pca$sdev^2 / sum(pca$sdev^2) plot(1-devs, main='Percent Variance Explained', type='l')

screeplot(pca)

Plot the PCs
Although we would need about 3 components to recover a large percent of the variance of the data. For illustration, we plot the mean image and the first 9 principal components (PCs).
V <- pca$rotation #sample PCs from PCA
################################
# Plotting Mean Image and PCs
################################
par(mfrow=c(2, 5))
par(oma = rep(2, 4), mar=c(0, 0, 3, 0))
makeimg(cmeans, main = 'Average Striper')
for (i in 1:9){
makeimg(V[,i],main = paste0('PC ', i)) #PCs from sample data
}

Conclusion
This post was more about congratulating Alyssa with some analysis, but I still want to discuss the results.
We can see some pattern in the data from the PCs, but you need many PCs to explain a larger percent of the variance in the data. That is not surprising; this data is not standardized in the way people took the pictures, such as front-facing, with different backgrounds, and I’m using the color information rather than black and white.
We would likely also have more interpretable results if we registered images. In neuroimaging, we register brains to each other and average them to make a template image. We could do that in this analysis and should do so if this was a real project and not a post.
Moreover, we are doing a PCA on non-negative values bounded between 0 and 1. I think this is one of the most interesting aspects of the data. In many analyses using PCA we actually always have positive values. For example people’s food choices is one example where non-negative matrix factorization is used; you can’t eat negative calories…if only. I think this is something to look into for people who are doing PCA on strictly positive values. Although you demean and scale the data and make values negative, you can re-construct data from this components and their scores to get non-interpretable values such as those outside [0, 1]. I’m looking into the nsprcomp package for non-negative PCA for future research work.
