In R, useful functions for making design matrices are model.frame and model.matrix. I will to discuss some of the differences of behavior across and within the two functions. I also have an example where I have run into this problme and it caused me to lose time.
Using model.frame for a design matrix
Whenever I use the word “design” I mean the sytematic part of a model; in this case, linear models. For example, if you say

I'm referring to the 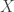
model.frame creates a design data.frame of the covariates given, keeping any factor variables as factors with the same levels. Let's create a toy data.frame called df, where Y is a normal random variable linearly related to two variables in the dataset:
n = 100
df = data.frame(X1 = rnorm(n),
X2 = rpois(n, lambda = 5),
X3= rnorm(100, mean = 4, sd = 2),
Sex = factor(rep(c("Male", "Female"), each = 50)))
df$Y = with(df, X1 + 3*X2 + rnorm(100, sd = 10))
Now, if Y is included on the left hand side of the formula, then it is included in the output of model.frame as such:
model.df = model.frame(Y ~ X1 + X2 + X3 + Sex, data=df) head(model.df, 2)
Y X1 X2 X3 Sex 1 9.223 0.3849 2 5.960 Male 2 12.467 -0.5061 5 1.651 Male
This gives you a data.frame with the outcome and the covariates fitting that outcome (not including an intercept).
If Y is not included on the left hand side of the formula:
model.df2 = model.frame(~ X1 + X2 + X3 + Sex, data=df) head(model.df2, 2)
X1 X2 X3 Sex 1 0.3849 2 5.960 Male 2 -0.5061 5 1.651 Male
then we see that Y is not included in the output of model.frame. Thus, if you want to create a “design data.frame”, then you likely will want to remove Y from the formula.
Note, in both cases, we see that there is no intercept term added to the data.frame and nothing is done to factor variables.
Using model.matrix
Most cases I'm making model design elements is using model.matrix to then use matrix multiplications to make procedures faster or do “smarter” (i.e. fewer) computations. I will discuss the differences between model.frame and model.matrix using our toy dataset and also dicuss one gotcha) for using model.matrix and lm.
Let's use model.matrix with and without Y on the left hand side of the formula.
model.mat = model.matrix(Y ~ X1 + X2 + X3 + Sex, data=df) model.mat2 = model.matrix(~ X1 + X2 + X3 + Sex, data=df) all.equal(model.mat, model.mat2)
[1] TRUE
We see that using any element on the left hand side doesn't affect the output of model.matrix. Difference #1 from model.frame.
Let's look at the output from model.matrix.
head(model.mat, 3)
(Intercept) X1 X2 X3 SexMale 1 1 0.3849 2 5.960 1 2 1 -0.5061 5 1.651 1 3 1 -1.3739 3 3.197 1
We see a column was added named (Intercept) with a column of ones for the 
model.frame. Also, we see that our factor Sex was converted to an indicator (numeric) variable. Difference #3 from model.frame. We only have 2 levels in Sex in this example. In general, a factor with L levels will generate L - 1 indicator variables using model.matrix.
Review over, how did this affect me?
I wanted to discuss the differences above to note them if you haven't seen them before. Also, I want to show that using model.matrix and a -1 or 0 in a formula can affect how some of your results are calculated using linear models with lm. Running the model with our now-ready model matrix:
mod = lm(df$Y ~ model.mat) summary(mod)
Call:
lm(formula = df$Y ~ model.mat)
Residuals:
Min 1Q Median 3Q Max
-25.644 -8.617 0.448 7.648 30.245
Coefficients: (1 not defined because of singularities)
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.1871 3.9533 -0.81 0.42
model.mat(Intercept) NA NA NA NA
model.matX1 1.1894 1.0987 1.08 0.28
model.matX2 3.6243 0.5790 6.26 1.1e-08 ***
model.matX3 0.0164 0.5422 0.03 0.98
model.matSexMale 2.6174 2.2726 1.15 0.25
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 11.2 on 95 degrees of freedom
Multiple R-squared: 0.312, Adjusted R-squared: 0.283
F-statistic: 10.8 on 4 and 95 DF, p-value: 3.03e-07
We see that the intercept term created in model.matrix was made NA because it's identical to the intercept term inherently generated by R and is linearly dependent. This is also seen with the warning: “(1 not defined because of singularities)”. This is good to know, but not revelatory or new; just be aware.
When model.matrix goes … differently
Well model.mat already has an intercept, so why not just take out the intercept term with a -1? The model should be the same, right? I would assume this is the case, but let's do it:
mod.noint = lm(df$Y ~ model.mat - 1) summary(mod.noint)
Call:
lm(formula = df$Y ~ model.mat - 1)
Residuals:
Min 1Q Median 3Q Max
-25.644 -8.617 0.448 7.648 30.245
Coefficients:
Estimate Std. Error t value Pr(>|t|)
model.mat(Intercept) -3.1871 3.9533 -0.81 0.42
model.matX1 1.1894 1.0987 1.08 0.28
model.matX2 3.6243 0.5790 6.26 1.1e-08 ***
model.matX3 0.0164 0.5422 0.03 0.98
model.matSexMale 2.6174 2.2726 1.15 0.25
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 11.2 on 95 degrees of freedom
Multiple R-squared: 0.717, Adjusted R-squared: 0.702
F-statistic: 48.1 on 5 and 95 DF, p-value: <2e-16
We see the intercepts look exactly the same (except we have removed the NA). But note the r.squared, adjusted.r.squared and F-statistic values!
Let's focus on 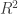
summary(mod)$r.squared
[1] 0.3121
summary(mod.noint)$r.squared
[1] 0.7168
These are different – way different – which seems off. Why? If you look into the summary.lm code, you will notice a some of statements involve the expression:
attr(z$terms, "intercept")
and calculate quantities differently depending on whether it flags that test as TRUE or FALSE.
Let's look our two models again from model.matrix:
attr(mod$terms, "intercept")
[1] 1
attr(mod.noint$terms, "intercept")
[1] 0
We see that when you construct the intercept yourself, this code evaluates to FALSE, even though the model has an “intercept”. The model has an intercept, but R hasn't assigned it that attribute. This effects the calculation of the model sum of squares (from summary.lm):
mss <- if (attr(z$terms, "intercept")) sum((f - mean(f))^2) else sum(f^2)
as well as others. So be aware of this behavior.
Conclusion
I was writing something for a linear model that allowed me to compute a large number of regressions (> 1,000,000) on a matrix of outcomes with a fixed adjustment matrix and changing 1 piece of the design matrix. I was doing a voxel-on-scalar regression with covariate adjustment, but also wanted to incorporate the ability to compute the results on a matrix of permutations of Y.
Either way, I ran into a problem checking my results against the output from lm and it took a while to see why the r.squared values were different but all other elements the same. I realized that this was because I was constructing my own design matrix using model.matrix and was using -1 when running lm and those results were not being calculated correctly. Hope you don't run into this problem ever.
Aside: What I wanted to do
Just to be precise, my model was:

where 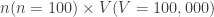





lm commands versus running 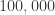
lm commands. (Doing this is not efficient – solving matrix inversions is time-consuming and should not be redundant). I wanted 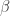
vows or limma can do these regressions – but they are usually when the design is fixed and not changing for every voxel and usually the end result is a p-value.
I have it working and may release it into the wild soon. Let me know if you know of anything that will do this, including covariate adjustment and where you can run for a matrix of permuted









